
Safety and Liveness Guarantees through Reach-Avoid Reinforcement Learning
Published in RSS, 2021
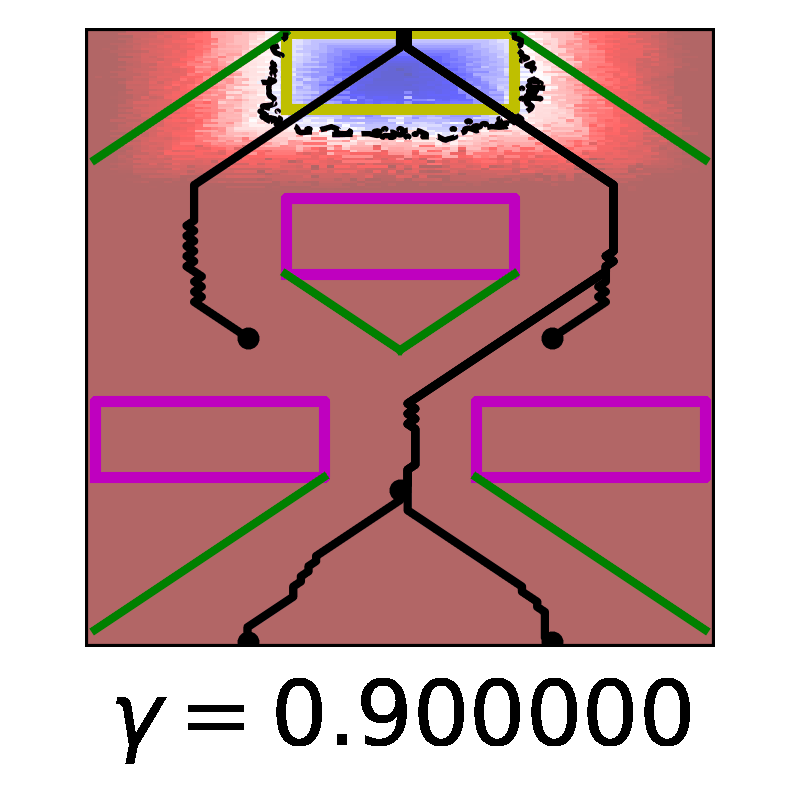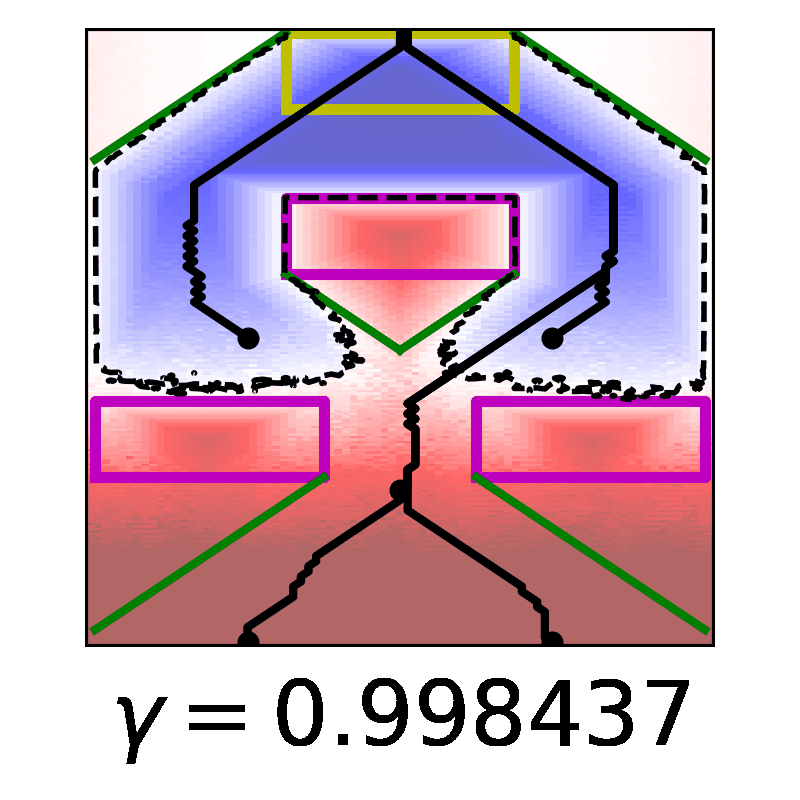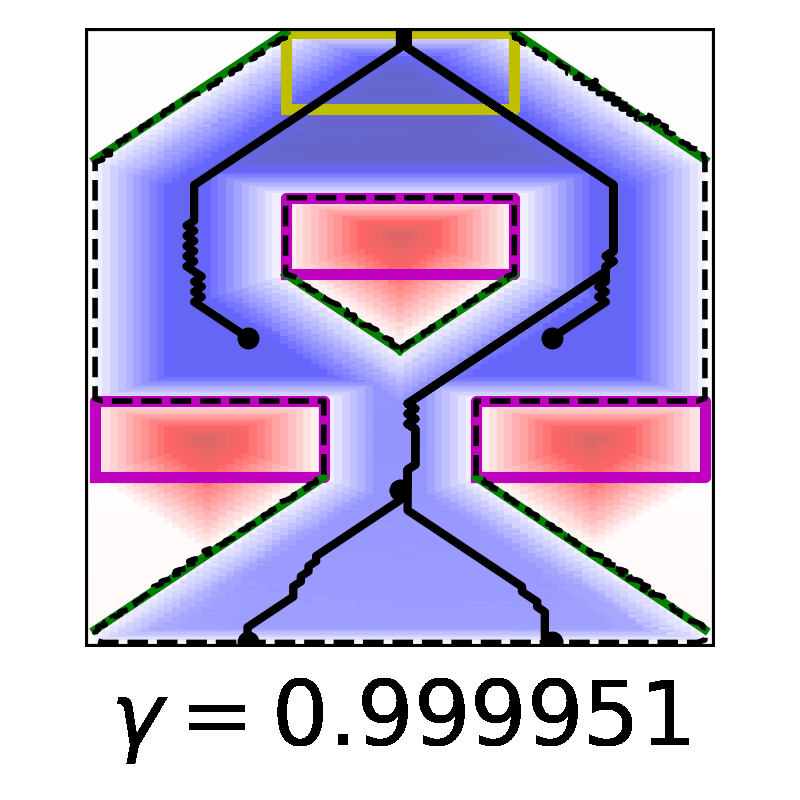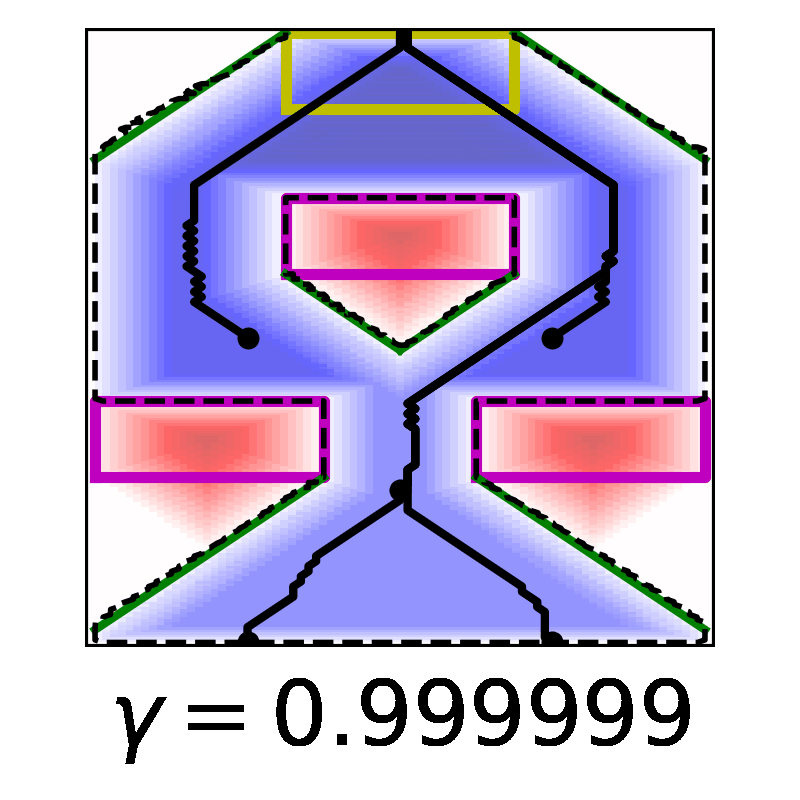
In this work, we derive a novel, time-discounted formulation of the reach-avoid optimal control problem that lends itself to reinforcement learning methods thanks to the contraction mapping. With the proposed formulation, we prove that the resulting zero sublevel set is a conservative under-approximation of the reach-avoid set, and in fact becomes arbitrarily tight as time discounting is phased out. Importantly, our guarantees can be extended to the use of deep reinforcement learning methods by treating the approximate optimal policy as an untrusted oracle and applying a supervisory control scheme: this insight is key, because it enables us to construct control policies with guaranteed safety and liveness for high-dimensional nonlinear systems that are intractable with classical approaches. To determine the reliability of the proposed method as a synthesis tool, we present comprehensive validation results against analytic and numerical solutions, and by exhaustive Monte Carlo simulation in two high-dimensional nonlinear systems.
Recommended citation:
@INPROCEEDINGS{hsu2021safety,
AUTHOR = {Kai-Chieh Hsu{\ast} and Vicenç Rubies-Royo{\ast} and Claire J. Tomlin and Jaime F. Fisac},
TITLE = {Safety and Liveness Guarantees through Reach-Avoid Reinforcement Learning},
BOOKTITLE = {Proceedings of Robotics: Science and Systems},
YEAR = {2021},
ADDRESS = {Held Virtually},
MONTH = {July},
DOI = {10.15607/RSS.2021.XVII.077}
}